Agentic vs Agentive: The Paper That Gets Agency Right and Accountability Wrong
The paper is right. And the industry will keep ignoring it because “agent” sells.
Eric Xing and collaborators at CMU/MBZUAI just published Critique of Agent Model, a 40+ page treatise that drops the most useful taxonomy I’ve seen for the “what is an agent?” debate: agentic vs agentive.
- Agentic systems complete tasks through tools and workflows built around a reasoning model. The smarts live in the scaffolding.
- Agentive systems generate their own capabilities from within. Goals, identity, decision-making, self-correction - all emerge from the model itself.
By this definition, every “agent” shipping today - Claude Code, Cursor, Copilot, Devin, your custom LangGraph pipeline - is agentic. Not agentive. The competence is in the harness, the MCP servers, the tool definitions, the workflow graphs. Not in the model’s own internalized decision architecture.
I wrote about this exact confusion six months ago. Five competing definitions, no consensus. Xing’s paper cuts through it cleanly.
What the Paper Gets Right
The core contribution is a formal decomposition of agency along five dimensions:
| Dimension | Agentic (Today) | Agentive (Paper’s Goal) |
|---|---|---|
| Goals | User-supplied prompts, gone after the session ends | Persistent, internally decomposed over time |
| Identity | Static system prompts, config files | Evolves through experience, self-revises |
| Decision-making | Fixed workflows, predefined tool chains | Plans by imagining what happens next |
| Self-regulation | Designer-prescribed execution modes | Decides how hard to think, adapts on the fly |
| Learning | Frozen after training, needs redeployment | Continuous, self-directed |
This maps to what practitioners already know intuitively. I’ve been writing about harness engineering for months: when your agent fails, the problem is almost never the model. It’s everything around it. That “everything around it” is exactly what Xing calls the agentic layer.
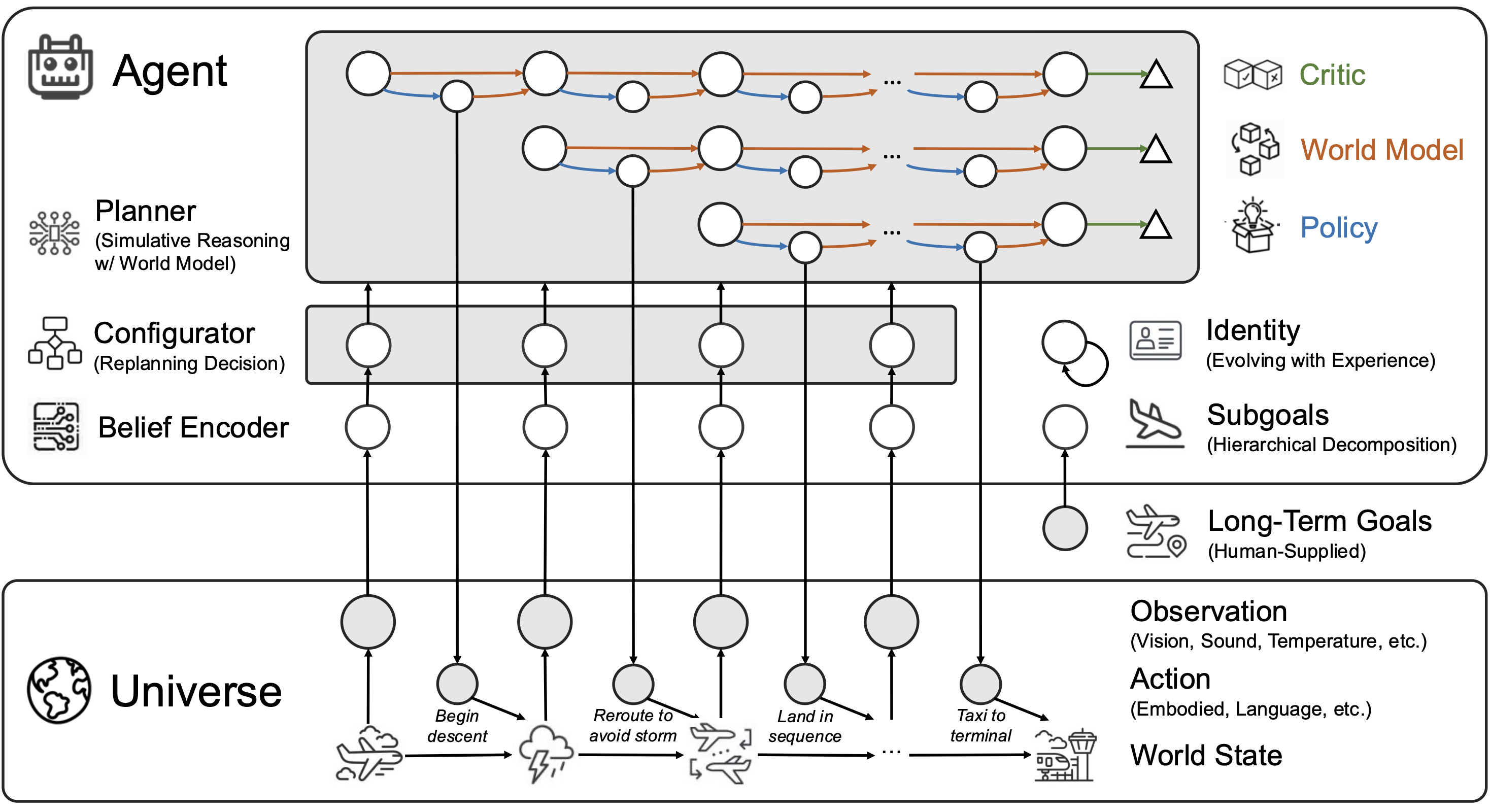
GIC: The Paper’s Proposed Architecture
The paper proposes GIC (Goal-Identity-Configurator) - an architecture where these five dimensions are internalized into a unified learned model. The premise is simple: humans don’t need new scaffolding for every task. One cognitive architecture handles coding, mountain climbing, and social negotiation alike.
Current AI agents can’t do this. Each new capability requires new tools, new MCP servers, new workflow definitions. The paper argues this won’t scale.
GIC’s answer has three parts:
- Goal module - breaks long-term objectives into subgoals internally, persisting across sessions
- Identity module - a self-model that evolves with experience (not a static system prompt)
- Configurator - the novel piece: a meta-controller that decides when and how deeply to plan
The Configurator is the interesting bit. Should the agent react immediately? Engage in full simulative planning? Or skip planning because it already has a good-enough plan from the last step? The paper shows this learned regulation uses 25–95% fewer reasoning tokens than always-on planning, while matching or exceeding accuracy.
It’s intellectually rigorous. The math is clean. The taxonomy is correct.
And it completely misses what matters to the people writing the checks.
The 40-Page Blind Spot
40+ pages on how to make agents increasingly autonomous. A single paragraph on how institutions remain in control.
Here’s where I stopped reading and started arguing with the paper.
To be fair: the paper does address safety. Its argument rests on two claims:
“Harmful behavior decomposes entirely into two categories: goal misspecification (i.e., the human supplied the wrong objective) and component imperfection (i.e., a module made a mistake while pursuing the goal).”
And the architecture’s defense:
“GIC provides natural checkpoints for human oversight at every layer.”
What does that oversight look like? Goal decomposition “can be audited to detect undesirable instrumental subgoals.” Identity evolution “can be monitored over time to verify that an appropriate self-model is developing.” The Configurator’s decisions “can be audited to verify that deliberation is allocated proportionally to task importance.”
The paper even draws an aviation analogy: pilots crash during training, so we built simulators and staged curricula. GIC trains in a world model sandbox before real deployment. Their conclusion:
“From this perspective, building agents with the right architecture is itself a safety intervention.”
This is transparency for debugging. Not accountability for regulators. The paper imagines researchers inspecting modules during development. It does not imagine a compliance officer asking “who approved this decision, under which policy version, and where’s the audit trail I can hand to a regulator?”
That’s the gap. Not a missing feature. A missing audience.
I’ve spent the last year deploying AI systems in regulated financial services, where “the model was interpretable” does not satisfy an auditor. They don’t care about your architecture diagrams. They want the decision trail. They want version-controlled policy. They want to know who approved what, when, and under which rule version.
Autonomy vs Accountability: Different Objectives
The paper assumes the next problem is: How do we build a truly autonomous agent?
Regulated enterprises have a fundamentally different problem: How do we execute at scale while remaining auditable, explainable, and legally defensible?
Those are different objectives. They lead to different architectures. And they’re not just preferences - they’re legal requirements.
- Banking (OCC SR 11-7): Every model must be validated, documented, and monitored. An agent that “learns continuously” would change without re-validation - a direct compliance violation.
- EU AI Act: High-risk systems need human oversight, record-keeping, and risk management. A Configurator that silently decides to skip planning on a high-stakes decision? Good luck explaining that to a regulator.
- Healthcare (FDA SaMD): Clinical decision support that learns from outcomes without governance would require a new regulatory submission with each meaningful update.
These aren’t theoretical concerns. They’re the reason accountability-first isn’t a design preference - it’s a hard constraint.
| Concern | Autonomy-First (Paper) | Accountability-First (Enterprise) |
|---|---|---|
| Goal | Agent decomposes its own goals | Human approves every subgoal above a risk threshold |
| Identity | Agent evolves its own capabilities | Capabilities are version-controlled and change-managed |
| Decision-making | Agent selects autonomously | Agent proposes, human approves |
| Self-regulation | Agent decides when to think harder | Policy engine decides what the agent can even attempt |
| Learning | Agent improves continuously | Updates go through validation, staging, regression |
A bank doesn’t want its loan approval agent to “evolve its identity” based on experience. It wants the agent to execute a defined decision policy, log every step, and produce an audit trail that satisfies regulators.
A hospital doesn’t want its clinical decision support agent to “self-direct its learning.” It wants validated clinical pathways, physician review at deviation points, and chain of custody for every recommendation touching a patient record.
What Accountability-First Architecture Looks Like
Let me make this concrete. Say you’re building a claims processing agent for an insurance company. A customer submits a water damage claim with photos, receipts, and a contractor estimate.
The autonomy-first version (GIC) would handle it like this:
Customer claim → Agent decomposes goal → Agent reasons about coverage
→ Agent calculates payout
→ Agent pays claim
(all internal, all learned, no external gates)The accountability-first version (what actually ships) inverts the control:
┌─────────────────────────────────────────┐
│ Human Review (approve/override payout) │
├─────────────────────────────────────────┤
│ Policy Engine (coverage rules, limits) │
├─────────────────────────────────────────┤
│ Audit Logger (every decision, versioned)│
├─────────────────────────────────────────┤
│ Harness (orchestrate, checkpoint) │
├─────────────────────────────────────────┤
│ Isolation (customer data stays bounded)│
├─────────────────────────────────────────┤
│ LLM Agent (extract, summarize, propose)│
└─────────────────────────────────────────┘The agent sits at the bottom. It extracts, summarizes, and proposes. It doesn’t decide. Everything above it constrains, logs, and governs that proposal.
When a regulator asks “why was claim #8847 paid at 80%?”:
| Architecture | The answer |
|---|---|
| Autonomy-first | ”The model’s internal world model simulated the scenario and selected this action.” |
| Accountability-first | ”Policy rule v2.3 applied. Here’s the extraction. Here’s who approved it. Here’s the timestamp.” |
One of these keeps you out of court.
When Things Go Wrong
Now imagine the agent misclassifies a burst pipe as “flood” - which the policy excludes. The claim gets denied. The customer sues.
| GIC (Autonomy-First) | Accountability Stack | |
|---|---|---|
| Where’s the error? | Agent “evolved its identity” from past claims - maybe a bias from skewed training | Extraction model misclassified damage type |
| Who’s responsible? | Unclear - no static policy, no version to roll back | Three clear owners: model, policy rule, reviewer |
| Can you replay it? | No - Configurator skipped planning because it “had a good-enough plan” | Yes - every step logged with inputs and rule versions |
| The fix | Retrain the whole agent? Unclear which component drifted | Retrain extractor, add confidence threshold, flag for review |
The paper promises “diagnosable and fixable” at the architecture level. Regulated environments need it at the institutional level.
The Human Review Trap
There’s a failure mode in the accountability stack too. I’ve seen it firsthand: alert fatigue.
A claims adjuster seeing 200 agent proposals a day will rubber-stamp them. The human approval step becomes a checkbox, not a check.
The fix isn’t removing the human. It’s making the review meaningful:
| Pattern | How it works |
|---|---|
| Risk-based routing | Only surface high-risk or low-confidence decisions. Auto-approve routine claims, but flag them: “auto-approved under policy rule X, version Y.” |
| Forced counter-arguments | Before the human sees a recommendation, the harness generates a devil’s advocate case: “Here’s why this might be underpaid.” Two seconds to read. Breaks the rubber-stamp reflex. |
| Rotation and sampling | Randomly escalate a percentage of auto-approved decisions for human audit. Keeps reviewers calibrated. |
This is harness design, not model design. Another thing the paper doesn’t touch.
The inversion the paper misses: The agent is a component, not the system. The system is the governance stack around it.
Why “Agent” Sells and “Orchestrator” Doesn’t
The paper is taxonomically correct. Most production “agents” are orchestrators - fancy if-else trees with an LLM in the loop.
But nobody raises a Series B by pitching “we built a really good orchestrator.”
"Agent" → Autonomy → Less human labor → Margin expansion → $50M valuation
"Orchestrator" → Tools → Same humans → Same margins → Series A, maybeThat’s why the term persists despite being technically wrong for 95% of deployed systems.
Xing’s paper won’t change this. What actually ships in regulated environments:
- A well-constrained LLM
- Inside a carefully engineered harness
- With human oversight at every high-stakes decision point
That’s not an “agent.” That’s a really good tool.
The Bottom Line
The paper makes a genuine contribution. The agentic/agentive distinction is the clearest framing I’ve seen for where today’s systems sit on the autonomy spectrum. Read it.
And the Configurator - learned meta-reasoning about when to plan deeply - is genuinely valuable. I’d use it inside an accountability stack:
An agent that burns 95% fewer tokens on routine claims while escalating novel ones to full reasoning? That’s a feature. Wrap it in policy constraints, log its skip/plan decisions, let a human set the confidence thresholds. The research becomes useful the moment it accepts a governance boundary.
But the paper reveals the field’s deepest assumption: that the goal is increasing autonomy.
For research labs, that’s the right question.
For the enterprises that will deploy 90% of these systems in production, the question was never “how autonomous can we make this?”
It was always “how do we make this accountable?”
Different objectives. Different architectures. And a 40-page paper that still doesn’t have a serious answer for the people who actually need one.
Building AI agents for regulated industries? I’d love to hear how you’re solving the accountability problem. Reach out on LinkedIn.